How to Debug Agents with LangSmith and Label Studio

0. Label Studio Requirements
After section 5, this tutorial showcases one or more features available only in Label Studio paid products. We recommend creating a Starter Cloud trial to follow the tutorial.
1. Installation & Setup
First, install the required dependencies:
!pip install langchain langchain-openai langchain-community langsmith label-studio-sdk python-dotenv arxivEnvironment Configuration
You’ll need to configure the following environment variables in a .env file:
# Langsmith Configuration
# Get your API key and setup project at: https://docs.langchain.com/langsmith/home
LANGSMITH_API_KEY=your_langsmith_api_key
LANGSMITH_PROJECT=your_project_name
LANGSMITH_TRACING=true
# Label Studio Configuration
# Get your API key from Label Studio settings: https://docs.humansignal.com/
LABEL_STUDIO_URL=https://app.humansignal.com # or your Label Studio instance URL
LABEL_STUDIO_API_KEY=your_label_studio_api_key
# OpenAI Configuration (for the agent)
OPENAI_API_KEY=your_openai_api_keyLangSmith Setup: Visit LangSmith Documentation to create an account, get your API key, and set up a project for tracing.
Label Studio Setup: Visit Label Studio Documentation for installation instructions and how to generate an API token from your account settings.
Two Ways to Look at Your Data in Agentic Apps
| 👁️ AI Engineer | 👁️ AI Domain Expert |
|---|---|
 |
 |
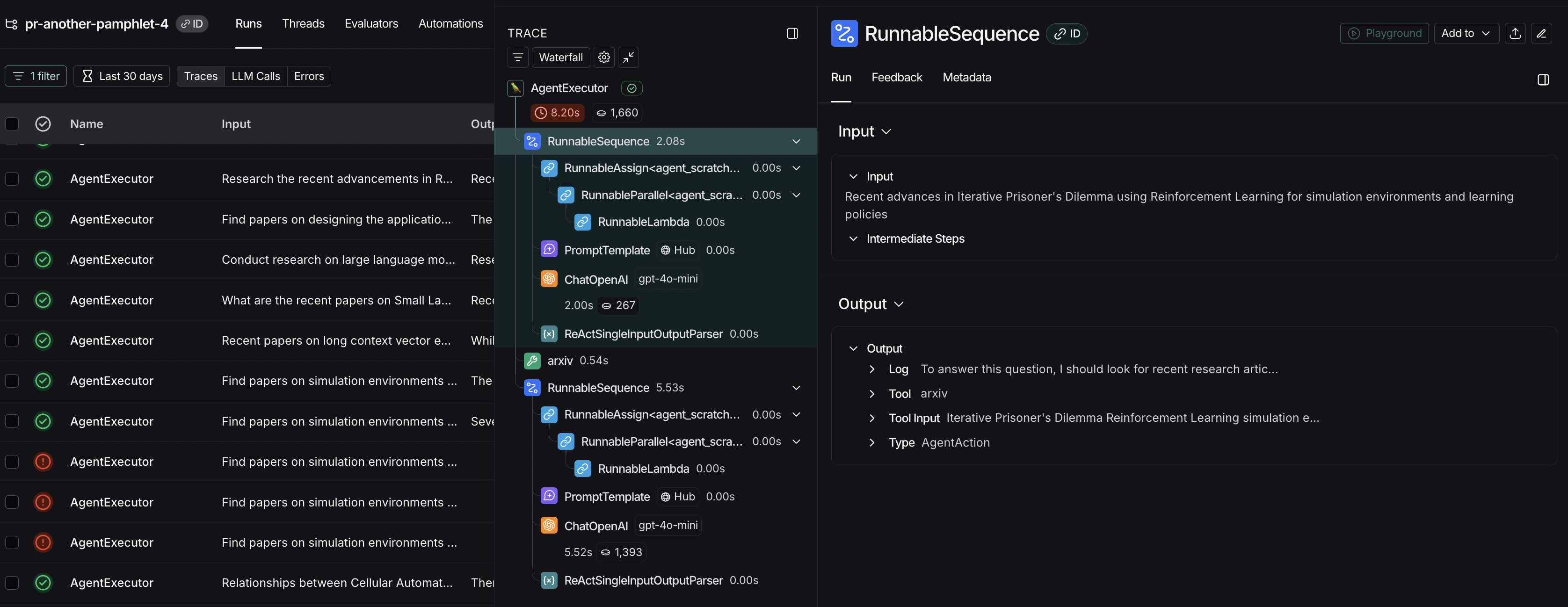
Problem: Where Did My Agent Fail?
AI agent apps become hard to debug and improve as they grow more complex. Teams commonly struggle with:
- Too much complexity: RAG pipelines, LLM calls, and multi-step conversations make it hard to know where problems occur
- Getting stuck: After building prototypes, teams can’t figure out what works, what breaks, or what to fix first
- Missing expertise: Engineers often don’t have the domain knowledge needed to properly evaluate their app’s performance
The core activity proposed to address these issues is simply “Look at your data”.
However, who should look at the data is often unclear, yet this determines project success.
Our Solution: Give it to your Domain Expert
We bridge this gap with a domain expert-centric UI that enables non-technical subject matter experts to systematically evaluate agent performance, complementing existing observability tools. This tutorial shows how to create an intuitive evaluation interface that transforms domain expertise into actionable improvements for your AI agents.
Setup: Build Your Agent Evaluation Pipeline
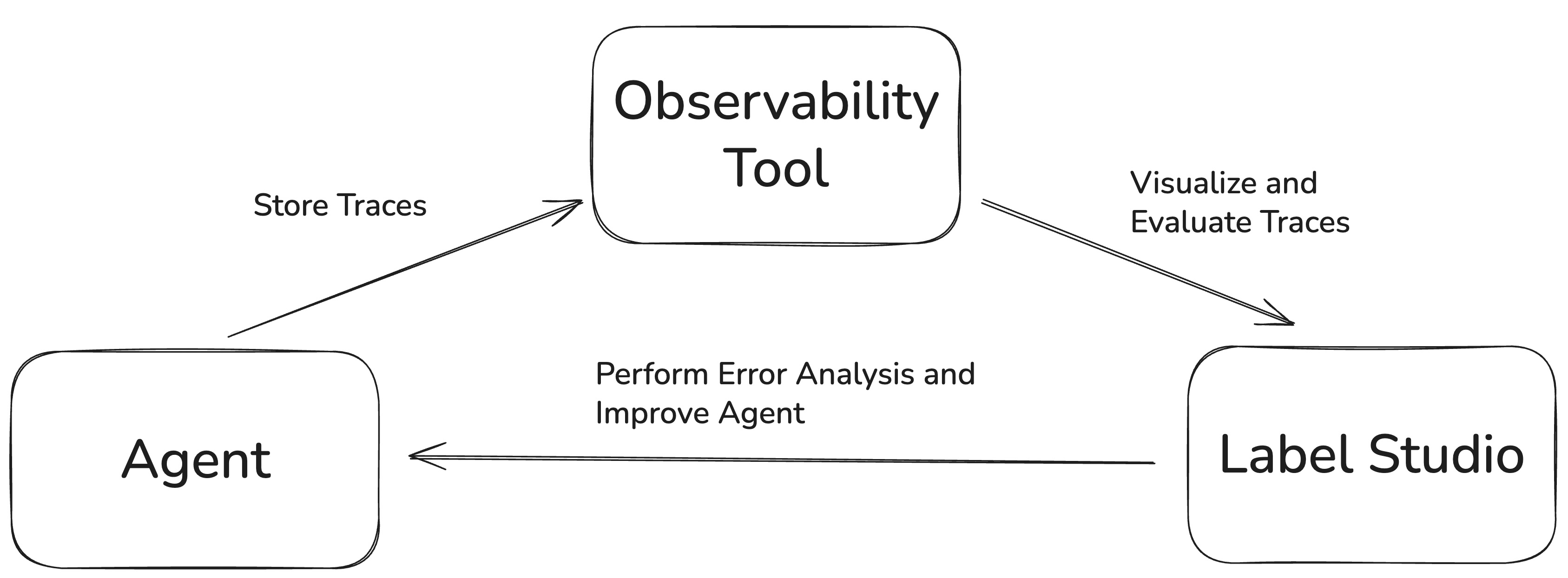
This tutorial demonstrates a complementary pipeline design for AI agent evaluation:
Step 1: Observability & Trace Collection
- Use observability tools (like Langsmith in this demo) for trace storage and collection
- Engineer-centric interface for technical debugging and development iteration
- Captures detailed execution traces, timing, and system-level metrics
- Provides immediate feedback during development cycles
Step 2: Expert-Centric Evaluation in Label Studio
- Import traces from observability tools into Label Studio for human evaluation
- Expert-centric, multi-user collaborative platform designed for domain specialists
- Detailed UI for systematic assessment of each step in agentic workflows
- Enables domain experts (SMEs) to identify and annotate failure modes
- Supports team-based annotation workflows with inter-annotator agreement
- Quality control features including annotation review and consensus building
- Generates structured evaluation data for reports and LLM-as-a-Judge training
Pipeline Benefits:
- Engineers get technical observability while domain experts get intuitive evaluation tools
- Traces flow seamlessly from development (observability) to evaluation (Label Studio)
- Combines technical metrics with human domain expertise for comprehensive assessment
- Note: While we use Langsmith as our demo observability tool, this approach works with any trace collection system
import os
from dotenv import load_dotenv
load_dotenv()
# Verify environment variables are loaded
required_vars = ['LANGSMITH_API_KEY', 'LANGSMITH_PROJECT', 'LABEL_STUDIO_URL', 'LABEL_STUDIO_API_KEY', 'OPENAI_API_KEY']
missing_vars = [var for var in required_vars if not os.getenv(var)]
if missing_vars:
print(f"⚠️ Missing environment variables: {', '.join(missing_vars)}")
print("Please configure these in your .env file before proceeding.")
else:
print("✓ All environment variables loaded successfully")✓ All environment variables loaded successfully
2. Running the Agent
We’ll create a simple ReAct agent that can search academic papers on Arxiv. This agent simulates a production use case where we help researchers find relevant papers on specific topics.
The agent uses:
- GPT-4o as the reasoning engine
- Arxiv tool to search academic papers
- LangSmith tracing to capture all interactions automatically
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableConfig
from uuid import uuid4
# Initialize LLM and Tools
llm = ChatOpenAI(model='gpt-4o')
tools = load_tools(["arxiv"])
# Pull the ReAct prompt template
prompt = hub.pull("hwchase17/react")
# Create the agent
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True,
)
print("✓ Agent initialized and ready")✓ Agent initialized and ready
Running Agent Examples
Let’s simulate a user asking questions about latest research:
questions = [
"What is the latest research on Visual Language Models?",
"Find papers about reinforcement learning in robotics from the last year",
"Explain the latest innovations in transformer architectures based on recent papers"
]
for i, question in enumerate(questions, 1):
config = RunnableConfig(run_id=str(uuid4()))
result = agent_executor.invoke({"input": question}, config=config)
print(f"\n✓ Run {i} completed. Run ID: {config.get('run_id')}")
print(f"Question: {question}")
print(f"Response: {result['output'][:200]}...")[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3mTo answer this question, I should search for the latest research articles on Visual Language Models on arXiv. This will provide me with the most recent developments and studies in this field.
Action: arxiv
Action Input: "Visual Language Models" latest[0m[36;1m[1;3mNo good Arxiv Result was found[0m[32;1m[1;3mIt seems that the search query needs to be adjusted to find relevant and recent papers on Visual Language Models. I should try using related terms or recent developments in Visual Language Models to refine the search.
Action: arxiv
Action Input: "Visual Grounding Language Models 2023"[0m[36;1m[1;3mPublished: 2024-01-09
Title: Expand BERT Representation with Visual Information via Grounded Language Learning with Multimodal Partial Alignment
Authors: Cong-Duy Nguyen, The-Anh Vu-Le, Thong Nguyen, Tho Quan, Luu Anh Tuan
Summary: Language models have been supervised with both language-only objective and
visual grounding in existing studies of visual-grounded language learning.
However, due to differences in the distribution and scale of visual-grounded
datasets and language corpora, the language model tends to mix up the context
of the tokens that occurred in the grounded data with those that do not. As a
result, during representation learning, there is a mismatch between the visual
information and the contextual meaning of the sentence. To overcome this
limitation, we propose GroundedBERT - a grounded language learning method that
enhances the BERT representation with visually grounded information.
GroundedBERT comprises two components: (i) the original BERT which captures the
contextual representation of words learned from the language corpora, and (ii)
a visual grounding module which captures visual information learned from
visual-grounded datasets. Moreover, we employ Optimal Transport (OT),
specifically its partial variant, to solve the fractional alignment problem
between the two modalities. Our proposed method significantly outperforms the
baseline language models on various language tasks of the GLUE and SQuAD
datasets.
Published: 2023-02-25
Title: Visually-Augmented Language Modeling
Authors: Weizhi Wang, Li Dong, Hao Cheng, Haoyu Song, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, Furu Wei
Summary: Human language is grounded on multimodal knowledge including visual knowledge
like colors, sizes, and shapes. However, current large-scale pre-trained
language models rely on text-only self-supervised training with massive text
data, which precludes them from utilizing relevant visual information when
necessary. To address this, we propose a novel pre-training framework, named
VaLM, to Visually-augment text tokens with retrieved relevant images for
Language Modeling. Specifically, VaLM builds on a novel latent text-image
alignment method via an image retrieval module to fetch corresponding images
given a textual context. With the visually-augmented context, VaLM uses a
visual knowledge fusion layer to enable multimodal grounded language modeling
by attending to both text context and visual knowledge in images. We evaluate
VaLM on various visual knowledge-intensive commonsense reasoning tasks, which
require visual information to excel. The experimental results illustrate that
VaLM outperforms all strong language-only and vision-language baselines with
substantial gains in reasoning object commonsense including color, size, and
shape. Our code is available at https://github.com/Victorwz/VaLM.
Published: 2023-02-13
Title: Like a bilingual baby: The advantage of visually grounding a bilingual language model
Authors: Khai-Nguyen Nguyen, Zixin Tang, Ankur Mali, Alex Kelly
Summary: Unlike most neural language models, humans learn language in a rich,
multi-sensory and, often, multi-lingual environment. Current language models
typically fail to fully capture the complexities of multilingual language use.
We train an LSTM language model on images and captions in English and Spanish
from MS-COCO-ES. We find that the visual grounding improves the model's
understanding of semantic similarity both within and across languages and
improves perplexity. However, we find no significant advantage of visual
grounding for abstract words. Our results provide additional evidence of the
advantages of visually grounded language models and point to the need for more
naturalistic language data from multilingual speakers and multilingual datasets
with perceptual grounding.[0m[32;1m[1;3mThe latest research on Visual Language Models explores various methods to enhance and ground language models with visual information. Here are some recent developments:
1. **GroundedBERT**: This study proposes a method to enhance BERT representations with visually grounded information. It combines BERT's contextual word representations with a visual grounding module that captures visual data. The approach uses Optimal Transport for partial alignment between these modalities and shows improved performance on language tasks compared to baseline models.
2. **VaLM (Visually-Augmented Language Modeling)**: This framework augments text tokens with images retrieved based on the textual context to enrich language models with visual knowledge such as colors, sizes, and shapes. The visually augmented context is processed using a visual knowledge fusion layer. VaLM has shown substantial improvements in visual commonsense reasoning tasks over traditional language-only models and vision-language baselines.
3. **Bilingual Language Modeling with Visual Grounding**: This research trains an LSTM model using bilingual (English and Spanish) datasets with visual grounding. It finds that visual grounding enhances the model's semantic understanding across languages and improves perplexity but does not significantly benefit the comprehension of abstract terms. This highlights the potential of visually grounded models but also their limitations with abstract language.
These studies indicate ongoing efforts to integrate visual information into language models for improved performance in multimodal and multilingual contexts.[0mInvalid Format: Missing 'Action:' after 'Thought:'[32;1m[1;3mFinal Answer: The latest research in Visual Language Models includes several innovative approaches:
1. **GroundedBERT**: This method enhances BERT with visually grounded information to improve the contextual understanding of text by addressing misalignments between text and visual data using Optimal Transport. It has shown superior performance on language tasks like GLUE and SQuAD.
2. **VaLM (Visually-Augmented Language Modeling)**: VaLM incorporates visual information by augmenting text with context-relevant images, using a visual knowledge fusion layer. It has demonstrated improved performance in visual commonsense reasoning tasks, surpassing both language-only and vision-language models.
3. **Bilingual Language Modeling with Visual Grounding**: This research employs visual grounding in bilingual (English-Spanish) language models to enhance semantic similarity understanding across languages, although it shows less impact on abstract concepts. It underscores the benefits and limitations of using visual data in multilingual contexts.
These studies illustrate the significant impact of integrating visual information into language models, optimizing them for varied and complex tasks by providing them with additional contextual data from images.[0m
[1m> Finished chain.[0m
✓ Run 1 completed. Run ID: 2401fa2a-9e96-4bbb-9441-f48375729d2a
Question: What is the latest research on Visual Language Models?
Response: The latest research in Visual Language Models includes several innovative approaches:
1. **GroundedBERT**: This method enhances BERT with visually grounded information to improve the contextual under...
[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3mTo find papers about reinforcement learning in robotics from the last year, I should search the arXiv database with a query that includes "reinforcement learning", "robotics", and filters the results to the last year. This should provide relevant and recent academic papers on the topic.
Action: arxiv
Action Input: reinforcement learning robotics submittedDate:[2022-10-01 TO 2023-10-01][0m[36;1m[1;3mPublished: 2022-10-13
Title: A Concise Introduction to Reinforcement Learning in Robotics
Authors: Akash Nagaraj, Mukund Sood, Bhagya M Patil
Summary: One of the biggest hurdles robotics faces is the facet of sophisticated and
hard-to-engineer behaviors. Reinforcement learning offers a set of tools, and a
framework to address this problem. In parallel, the misgivings of robotics
offer a solid testing ground and evaluation metric for advancements in
reinforcement learning. The two disciplines go hand-in-hand, much like the
fields of Mathematics and Physics. By means of this survey paper, we aim to
invigorate links between the research communities of the two disciplines by
focusing on the work done in reinforcement learning for locomotive and control
aspects of robotics. Additionally, we aim to highlight not only the notable
successes but also the key challenges of the application of Reinforcement
Learning in Robotics. This paper aims to serve as a reference guide for
researchers in reinforcement learning applied to the field of robotics. The
literature survey is at a fairly introductory level, aimed at aspiring
researchers. Appropriately, we have covered the most essential concepts
required for research in the field of reinforcement learning, with robotics in
mind. Through a thorough analysis of this problem, we are able to manifest how
reinforcement learning could be applied profitably, and also focus on
open-ended questions, as well as the potential for future research.
Published: 2022-09-07
Title: A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform
Authors: Z. Jiang, G. Song
Summary: With the development of industry, drones are appearing in various field. In
recent years, deep reinforcement learning has made impressive gains in games,
and we are committed to applying deep reinforcement learning algorithms to the
field of robotics, moving reinforcement learning algorithms from game scenarios
to real-world application scenarios. We are inspired by the LunarLander of
OpenAI Gym, we decided to make a bold attempt in the field of reinforcement
learning to control drones. At present, there is still a lack of work applying
reinforcement learning algorithms to robot control, the physical simulation
platform related to robot control is only suitable for the verification of
classical algorithms, and is not suitable for accessing reinforcement learning
algorithms for the training. In this paper, we will face this problem, bridging
the gap between physical simulation platforms and intelligent agent, connecting
intelligent agents to a physical simulation platform, allowing agents to learn
and complete drone flight tasks in a simulator that approximates the real
world. We proposed a reinforcement learning framework based on Gazebo that is a
kind of physical simulation platform (ROS-RL), and used three continuous action
space reinforcement learning algorithms in the framework to dealing with the
problem of autonomous landing of drones. Experiments show the effectiveness of
the algorithm, the task of autonomous landing of drones based on reinforcement
learning achieved full success.
Published: 2022-05-20
Title: Adversarial joint attacks on legged robots
Authors: Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto
Summary: We address adversarial attacks on the actuators at the joints of legged
robots trained by deep reinforcement learning. The vulnerability to the joint
attacks can significantly impact the safety and robustness of legged robots. In
this study, we demonstrate that the adversarial perturbations to the torque
control signals of the actuators can significantly reduce the rewards and cause
walking instability in robots. To find the adversarial torque perturbations, we
develop black-box adversarial attacks, where, the adversary cannot access the
neural networks trained by deep reinforcement learning. The black box attack
can be applied to legged robots regardless of the architecture and algorithms
of deep r[0m[32;1m[1;3mThe search returned relevant papers on reinforcement learning in robotics, published within the last year. Here are the details of the papers identified:
1. **A Concise Introduction to Reinforcement Learning in Robotics**
- **Published:** 2022-10-13
- **Authors:** Akash Nagaraj, Mukund Sood, Bhagya M Patil
- **Summary:** This paper provides a survey of reinforcement learning in robotics, discussing its potential to address complex behaviors in robotics and evaluating its successes and challenges. It's aimed at aspiring researchers and provides essential concepts needed for research in this field.
2. **A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform**
- **Published:** 2022-09-07
- **Authors:** Z. Jiang, G. Song
- **Summary:** This paper explores the application of deep reinforcement learning for the autonomous landing of drones. The authors propose a framework using a physical simulation platform and demonstrate the effectiveness of continuous action space reinforcement learning algorithms for this task.
3. **Adversarial Joint Attacks on Legged Robots**
- **Published:** 2022-05-20
- **Authors:** Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto
- **Summary:** This study addresses adversarial attacks on the actuators of legged robots trained by deep reinforcement learning. The paper explores black-box adversarial attacks to demonstrate the vulnerability of robots and the impact on their stability and safety.
These papers provide a broad insight into recent research and developments in the use of reinforcement learning in robotics.[0mInvalid Format: Missing 'Action:' after 'Thought:'[32;1m[1;3mThe search returned relevant papers on reinforcement learning in robotics, published within the last year. Here are the details of the papers identified:
1. **A Concise Introduction to Reinforcement Learning in Robotics**
- **Published:** 2022-10-13
- **Authors:** Akash Nagaraj, Mukund Sood, Bhagya M Patil
- **Summary:** This paper provides a survey of reinforcement learning in robotics, discussing its potential to address complex behaviors in robotics and evaluating its successes and challenges. It's aimed at aspiring researchers and provides essential concepts needed for research in this field.
2. **A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform**
- **Published:** 2022-09-07
- **Authors:** Z. Jiang, G. Song
- **Summary:** This paper explores the application of deep reinforcement learning for the autonomous landing of drones. The authors propose a framework using a physical simulation platform and demonstrate the effectiveness of continuous action space reinforcement learning algorithms for this task.
3. **Adversarial Joint Attacks on Legged Robots**
- **Published:** 2022-05-20
- **Authors:** Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto
- **Summary:** This study addresses adversarial attacks on the actuators of legged robots trained by deep reinforcement learning. The paper explores black-box adversarial attacks to demonstrate the vulnerability of robots and the impact on their stability and safety.
These papers provide a broad insight into recent research and developments in the use of reinforcement learning in robotics.[0mInvalid Format: Missing 'Action:' after 'Thought:'[32;1m[1;3mHere are the recent papers on reinforcement learning in robotics from the last year:
1. **A Concise Introduction to Reinforcement Learning in Robotics**
- **Published:** 2022-10-13
- **Authors:** Akash Nagaraj, Mukund Sood, Bhagya M Patil
- **Summary:** This paper surveys the field of reinforcement learning in robotics, focusing on its application in addressing sophisticated behaviors in robotics and evaluating both its successes and challenges. It serves as a reference for aspiring researchers by introducing essential concepts needed for research in this area.
2. **A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform**
- **Published:** 2022-09-07
- **Authors:** Z. Jiang, G. Song
- **Summary:** The paper discusses using deep reinforcement learning for the autonomous landing of drones. It presents a framework utilizing physical simulation platforms, demonstrating the effectiveness of continuous action space reinforcement learning algorithms in achieving successful drone landings.
These papers highlight ongoing research and developments in the application of reinforcement learning techniques to robotics.[0mInvalid Format: Missing 'Action:' after 'Thought:'[32;1m[1;3mI found some recent papers related to reinforcement learning in robotics. Here are the details:
1. **A Concise Introduction to Reinforcement Learning in Robotics**
- **Published:** 2022-10-13
- **Authors:** Akash Nagaraj, Mukund Sood, Bhagya M Patil
- **Summary:** This paper surveys the field of reinforcement learning in robotics, highlighting its potential to address complex behaviors and challenges in robotics. It serves as an introductory reference for researchers interested in reinforcement learning applications in robotics.
2. **A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform**
- **Published:** 2022-09-07
- **Authors:** Z. Jiang, G. Song
- **Summary:** This study explores the use of deep reinforcement learning for the autonomous landing of drones, demonstrating the effectiveness of continuous action space reinforcement learning algorithms when integrated with a physical simulation platform.
These papers offer insights into the current research landscape of reinforcement learning in robotics from the last year.[0mInvalid Format: Missing 'Action:' after 'Thought:'[32;1m[1;3mI now know the final answer.
Final Answer: Here are some recent papers on reinforcement learning in robotics from the last year:
1. **A Concise Introduction to Reinforcement Learning in Robotics**
- **Published:** 2022-10-13
- **Authors:** Akash Nagaraj, Mukund Sood, Bhagya M Patil
- **Summary:** This paper provides a survey of reinforcement learning in robotics, focusing on its potential to address complex behaviors and evaluating both successes and challenges. It serves as a reference guide for aspiring researchers.
2. **A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform**
- **Published:** 2022-09-07
- **Authors:** Z. Jiang, G. Song
- **Summary:** The study applies deep reinforcement learning to the autonomous landing of drones using a physical simulation platform, demonstrating the effectiveness of continuous action space reinforcement learning algorithms.
These papers highlight ongoing research and developments in applying reinforcement learning techniques to robotics.[0m
[1m> Finished chain.[0m
✓ Run 2 completed. Run ID: e92abdf7-c2c0-4acf-b26f-f0cf18745595
Question: Find papers about reinforcement learning in robotics from the last year
Response: Here are some recent papers on reinforcement learning in robotics from the last year:
1. **A Concise Introduction to Reinforcement Learning in Robotics**
- **Published:** 2022-10-13
- **Authors...
[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3mTo answer this question, I will search for recent papers on transformer architectures on arXiv to get the latest innovations and developments.
Action: arxiv
Action Input: "latest innovations transformer architectures 2023"[0m[36;1m[1;3mPublished: 2023-06-02
Title: Transforming ECG Diagnosis:An In-depth Review of Transformer-based DeepLearning Models in Cardiovascular Disease Detection
Authors: Zibin Zhao
Summary: The emergence of deep learning has significantly enhanced the analysis of
electrocardiograms (ECGs), a non-invasive method that is essential for
assessing heart health. Despite the complexity of ECG interpretation, advanced
deep learning models outperform traditional methods. However, the increasing
complexity of ECG data and the need for real-time and accurate diagnosis
necessitate exploring more robust architectures, such as transformers. Here, we
present an in-depth review of transformer architectures that are applied to ECG
classification. Originally developed for natural language processing, these
models capture complex temporal relationships in ECG signals that other models
might overlook. We conducted an extensive search of the latest
transformer-based models and summarize them to discuss the advances and
challenges in their application and suggest potential future improvements. This
review serves as a valuable resource for researchers and practitioners and aims
to shed light on this innovative application in ECG interpretation.
Published: 2023-09-13
Title: Edge-MoE: Memory-Efficient Multi-Task Vision Transformer Architecture with Task-level Sparsity via Mixture-of-Experts
Authors: Rishov Sarkar, Hanxue Liang, Zhiwen Fan, Zhangyang Wang, Cong Hao
Summary: Computer vision researchers are embracing two promising paradigms: Vision
Transformers (ViTs) and Multi-task Learning (MTL), which both show great
performance but are computation-intensive, given the quadratic complexity of
self-attention in ViT and the need to activate an entire large MTL model for
one task. M$^3$ViT is the latest multi-task ViT model that introduces
mixture-of-experts (MoE), where only a small portion of subnetworks ("experts")
are sparsely and dynamically activated based on the current task. M$^3$ViT
achieves better accuracy and over 80% computation reduction but leaves
challenges for efficient deployment on FPGA.
Our work, dubbed Edge-MoE, solves the challenges to introduce the first
end-to-end FPGA accelerator for multi-task ViT with a collection of
architectural innovations, including (1) a novel reordering mechanism for
self-attention, which requires only constant bandwidth regardless of the target
parallelism; (2) a fast single-pass softmax approximation; (3) an accurate and
low-cost GELU approximation; (4) a unified and flexible computing unit that is
shared by almost all computational layers to maximally reduce resource usage;
and (5) uniquely for M$^3$ViT, a novel patch reordering method to eliminate
memory access overhead. Edge-MoE achieves 2.24x and 4.90x better energy
efficiency comparing with GPU and CPU, respectively. A real-time video
demonstration is available online, along with our open-source code written
using High-Level Synthesis.
Published: 2025-08-04
Title: YOLOv1 to YOLOv11: A Comprehensive Survey of Real-Time Object Detection Innovations and Challenges
Authors: Manikanta Kotthapalli, Deepika Ravipati, Reshma Bhatia
Summary: Over the past decade, object detection has advanced significantly, with the
YOLO (You Only Look Once) family of models transforming the landscape of
real-time vision applications through unified, end-to-end detection frameworks.
From YOLOv1's pioneering regression-based detection to the latest YOLOv9, each
version has systematically enhanced the balance between speed, accuracy, and
deployment efficiency through continuous architectural and algorithmic
advancements.. Beyond core object detection, modern YOLO architectures have
expanded to support tasks such as instance segmentation, pose estimation,
object tracking, and domain-specific applications including medical imaging and
industrial automation. This paper offers a comprehensive review of the YOLO
family, highlighting architectural innovations, performance benchmarks,
ext[0m[32;1m[1;3mWhile not directly applicable, the provided paper on YOLO highlights innovations in real-time object detection rather than transformers. It is clear I should focus on details specifically concerning transformers, especially in new roles or applications.
Here are some significant innovations from the retrieved papers on transformer architectures:
1. **Transformers in ECG Diagnosis**: Transformers, originally developed for natural language processing, have found new applications in ECG data analysis due to their ability to capture complex temporal relationships within biological signals. These models surpass traditional methods in real-time and accurate diagnostics, suggesting new potential for improving cardiovascular disease detection.
2. **Edge-MoE Vision Transformers**: Innovations like Edge-MoE reflect an effort to enhance the computational efficiency of Vision Transformers. This architecture combines multi-task learning with sparse activation of subnetworks, yielding performance gains while necessitating architectural innovations for hardware like FPGA. The methods utilized here, like reordering and approximations for softmax, illustrate ongoing efforts to balance performance with resource efficiency in transformers.
These examples demonstrate transformers stretching beyond natural language to domains like medical data analysis, with adaptations in hardware for efficiency. This expansion into diverse tasks showcases their adaptability and the continuous evolution of their architectures.
Final Answer: Recent innovations in transformer architectures include their application to ECG diagnostics for better capturing temporal relationships, and advancements like Edge-MoE, which enhance computational efficiency in Vision Transformers through novel FPGA architectural techniques.[0m
[1m> Finished chain.[0m
✓ Run 3 completed. Run ID: ae390f69-6922-43f1-a98a-36c5da9f1af8
Question: Explain the latest innovations in transformer architectures based on recent papers
Response: Recent innovations in transformer architectures include their application to ECG diagnostics for better capturing temporal relationships, and advancements like Edge-MoE, which enhance computational ef...3. Collecting Traces
Now that we’ve generated several agent interactions, we’ll:
- Connect to LangSmith and query Agent traces
- Filter for relevant run types (AgentExecutor, LLM, Tool, Retriever)
- Convert traces to Label Studio format with predictions
from langsmith import Client
import json
from datetime import datetime
import uuid
import random
import string
# Initialize Langsmith client
client = Client()
# Define filter to get relevant run types
# We want to capture the complete agent execution flow
filter_string = 'or(and(eq(name, "AgentExecutor"), eq(run_type, "chain")), eq(run_type, "llm"), eq(run_type, "tool"), eq(run_type, "retriever"))'
# Fetch all runs from the project
runs = client.list_runs(
project_name=os.getenv('LANGSMITH_PROJECT'),
filter=filter_string
)
# Sort runs by start_time for chronological processing
runs = sorted(runs, key=lambda run: run.start_time)
# Group runs by trace_id
traces = {}
for run in runs:
if run.trace_id not in traces:
traces[run.trace_id] = []
traces[run.trace_id].append(run.dict())
print(f"✓ Collected {len(traces)} traces from Langsmith")
print(f" Total runs: {len(runs)}")✓ Collected 24 traces from Langsmith
Total runs: 149
4. Handler Functions for Different Run Types
These functions convert different types of Langsmith runs into Label Studio’s chat message format. Each run type has specific data structures that need to be transformed appropriately.
# Agent requests LLM provider
AGENT_LLM_CALL = 'agent_llm_call'
# Agent receives response from LLM provider
AGENT_LLM_RESPONSE = 'agent_llm_response'
# Agent calls tool (e.g. API call)
AGENT_TOOL_CALL = 'agent_tool_call'
# Agent calls retriever
AGENT_RETRIEVER_CALL = 'agent_retriever_call'def handle_llm(run, messages):
"""
Handler for LLM runs (run_type: "llm").
Extracts user messages from inputs and assistant responses from outputs.
"""
# Extract user message from inputs if present
if 'inputs' in run and 'messages' in run['inputs']:
messages_input = run['inputs']['messages']
if messages_input and len(messages_input) > 0:
message_array = messages_input[0]
if message_array and len(message_array) > 0:
message = message_array[0]
if 'kwargs' in message and 'content' in message['kwargs']:
messages.append({
"content": message['kwargs']['content'],
"role": "user",
"_hs_meta": {
"role": AGENT_LLM_CALL
}
})
# Extract assistant response from outputs
if 'outputs' in run and 'generations' in run['outputs']:
generations = run['outputs']['generations']
if generations and len(generations) > 0:
generation = generations[0]
if 'text' in generation:
messages.append({
"content": generation['text'],
"role": "assistant",
"_hs_meta": {
"role": AGENT_LLM_RESPONSE
}
})
elif 'message' in generation:
message = generation['message']
if 'kwargs' in message and 'content' in message['kwargs']:
messages.append({
"content": message['kwargs']['content'],
"role": "assistant",
"_hs_meta": {
"role": AGENT_LLM_RESPONSE
}
})
def handle_tool(run, messages):
"""
Handler for Tool runs (run_type: "tool").
Creates assistant message with tool call and tool response message.
"""
# Tool metadata
tool_name = run.get('name', 'unknown_tool')
tool_call_id = str(uuid.uuid4())[:8]
# Extract tool input
tool_input = ""
if 'inputs' in run and 'input' in run['inputs']:
tool_input = run['inputs']['input']
# Add assistant message with tool call
messages.append({
"role": "assistant",
"tool_calls": [
{
"id": tool_call_id,
"type": "custom",
"custom": {
"name": tool_name,
"input": tool_input
}
}
],
"_hs_meta": {
"role": AGENT_TOOL_CALL
}
})
# Add tool response message
if 'outputs' in run and 'output' in run['outputs']:
messages.append({
"content": run['outputs']['output'],
"role": "tool",
"tool_call_id": tool_call_id
})
def handle_retriever(run, messages):
"""
Handler for Retriever runs (run_type: "retriever").
Extracts retrieval results and formats them as tool messages.
"""
if 'outputs' in run:
output_content = str(run['outputs'])
messages.append({
"content": f"Retriever result: {output_content}",
"role": "tool",
"_hs_meta": {
"role": AGENT_RETRIEVER_CALL
}
})
print("✓ Handler functions defined")✓ Handler functions defined
5. Convert Traces to Label Studio Format
This function transforms Langsmith traces into Label Studio’s task format.
The mode="predictions" parameter creates pre-annotations that annotators
can review and modify, speeding up the evaluation process.
Key Features:
- Preserves chronological order of agent interactions
- Maintains timestamps for temporal analysis
- Structures data to match Label Studio’s Chat interface
- Creates predictions for each message (except the initial user query)
def convert_trace_to_messages(trace_id, trace_runs, mode="input", from_name="chat"):
"""
Converts a trace (list of runs) to Label Studio format.
Args:
trace_id: Unique identifier for the trace
trace_runs: List of run dictionaries from a single trace
mode: Either "input" or "predictions"
- "input": Returns simple message list
- "predictions": Returns Label Studio task format with predictions
from_name: The from_name field for Label Studio predictions
Returns:
Dict with trace_id and either messages or Label Studio task structure
"""
messages = []
agent_executor_run = None
# Sort runs chronologically
sorted_runs = sorted(trace_runs, key=lambda r: r.get('start_time', ''))
# Find AgentExecutor run (the main chain)
trace_id_str = None
for run in sorted_runs:
if not trace_id_str and 'trace_id' in run:
trace_id_str = str(run['trace_id'])
if run.get('name') == 'AgentExecutor' and run.get('run_type') == 'chain':
agent_executor_run = run
break
# Extract initial user message from AgentExecutor
first_user_timestamp = None
if agent_executor_run:
if 'inputs' in agent_executor_run and 'input' in agent_executor_run['inputs']:
first_user_timestamp = agent_executor_run.get('start_time')
messages.append({
"content": agent_executor_run['inputs']['input'],
"role": "user",
"_timestamp": first_user_timestamp
})
# Process intermediate runs (llm, tool, retriever)
for run in sorted_runs:
run_type = run.get('run_type')
name = run.get('name')
# Skip the AgentExecutor itself
if name == 'AgentExecutor' and run_type == 'chain':
continue
# Track messages before processing
messages_before = len(messages)
# Apply appropriate handler
if run_type == 'llm':
handle_llm(run, messages)
elif run_type == 'tool':
handle_tool(run, messages)
elif run_type == 'retriever':
handle_retriever(run, messages)
# Attach timestamp to new messages
messages_after = len(messages)
run_timestamp = run.get('start_time')
for i in range(messages_before, messages_after):
if '_timestamp' not in messages[i]:
messages[i]['_timestamp'] = run_timestamp
# Add final assistant message from AgentExecutor output
if agent_executor_run:
if agent_executor_run.get('outputs') and 'output' in agent_executor_run['outputs']:
final_output = agent_executor_run['outputs']['output']
# Only add if different from last message
if not messages or messages[-1]['content'] != final_output:
messages.append({
"content": final_output,
"role": "assistant",
"_timestamp": agent_executor_run.get('end_time') or agent_executor_run.get('start_time')
})
# Return format depends on mode
if mode == "input":
# Clean format without timestamps
clean_messages = []
for msg in messages:
clean_msg = {k: v for k, v in msg.items() if k != '_timestamp'}
clean_messages.append(clean_msg)
return {"trace_id": str(trace_id_str), "messages": clean_messages}
# Mode is "predictions" - convert to Label Studio format
if mode == "predictions":
# Separate first user message from remaining messages
first_user_message = None
remaining_messages = []
for msg in messages:
if msg.get('role') == 'user' and first_user_message is None:
first_user_message = {k: v for k, v in msg.items() if k != '_timestamp'}
elif first_user_message is not None:
remaining_messages.append(msg)
# Convert remaining messages to predictions
predictions_result = []
for msg in remaining_messages:
# Generate unique ID for prediction
prediction_id = ''.join(random.choices(string.ascii_letters + string.digits, k=10))
# Parse timestamp
created_at = None
timestamp_value = msg.get('_timestamp')
if timestamp_value:
try:
if isinstance(timestamp_value, datetime):
dt = timestamp_value
elif isinstance(timestamp_value, str):
if 'T' in timestamp_value:
dt = datetime.fromisoformat(timestamp_value.replace('Z', '+00:00'))
else:
dt = datetime.fromisoformat(timestamp_value)
else:
dt = None
if dt:
created_at = int(dt.timestamp() * 1000)
except Exception as e:
print(f'Warning: Error parsing timestamp: {timestamp_value} - {e}')
# Fallback to current timestamp
if created_at is None:
created_at = int(datetime.now().timestamp() * 1000)
# Build prediction item
prediction_item = {
"id": prediction_id,
"type": "chatmessage",
"value": {
"chatmessage": {
"role": msg.get('role', 'assistant'),
"content": msg.get('content', ''),
"createdAt": created_at
}
},
"origin": "manual",
"to_name": "chat",
"from_name": from_name
}
# Include tool_calls if present
if 'tool_calls' in msg:
prediction_item['value']['chatmessage']['tool_calls'] = msg['tool_calls']
# prediction_item['value']['chatmessage'].pop('content', None)
# Include tool_call_id if present
if 'tool_call_id' in msg:
prediction_item['value']['chatmessage']['tool_call_id'] = msg['tool_call_id']
# Include _hs_meta if present
if '_hs_meta' in msg:
prediction_item['value']['chatmessage']['_hs_meta'] = msg['_hs_meta']
predictions_result.append(prediction_item)
# Build final task structure
task_data = {
"data": {
"trace_id": str(trace_id_str),
"messages": [first_user_message] if first_user_message else []
},
"predictions": [{
"result": predictions_result
}]
}
return task_data
return {"trace_id": str(trace_id_str), "messages": messages}
# Convert all traces to Label Studio format
tasks = []
for trace_id, trace_data in traces.items():
task = convert_trace_to_messages(trace_id, trace_data, mode="predictions")
tasks.append(task)
print(f"✓ Converted {len(tasks)} traces to Label Studio format")✓ Converted 24 traces to Label Studio format
6. Evaluate Traces
To run evaluation on the collected agent traces, use Label Studio XML configuration to provide a specialized UI with:
- Chat Display: Shows the full conversation with all agent interactions
- Message-Level Annotation: Click any message to annotate specific errors
- Role-Specific Error Categories:
- User errors (request issues)
- Assistant errors (hallucination, bias, format, etc.)
- Tool errors (tool malfunction or incorrect output)
- Overall Assessment: Rate the entire conversation
- Notes Fields: Capture detailed feedback from annotators
This configuration enables Subject Matter Experts (SMEs) to perform detailed failure mode analysis on each step of the agent’s reasoning process.
label_config = """<View>
<Style>
.htx-chat{flex-grow:1}
.htx-chat-sidepanel{flex:300px 0 0;display:flex;flex-direction:column;border-left:2px solid #ccc;padding-left:16px}
.htx-chat-container{display:flex;flex-direction:column;flex-grow:1}
.htx-overall-assessment{margin-top:16px;padding:16px;border:1px solid #e0e0e0;border-radius:8px;background:#fafafa}
</Style>
<View style="display:flex;width:100%;gap:1em">
<View className="htx-chat-container">
<Chat name="chat"
value="$messages"
llm="openai/gpt-5-mini"
editable="true"
messageroles="user,assistant,tool"
/>
<!-- Evaluate the whole conversation -->
<View className="htx-overall-assessment">
<Header value="Overall Assessment:"/>
<Choices name="overall_assessment" toName="chat" choice="single-radio" showInLine="true" required="true">
<Choice value="Contains Errors" hint="The conversation contains errors."/>
<Choice value="No Errors" hint="The conversation contains no errors."/>
</Choices>
<Header value="Leave notes:"/>
<TextArea name="overall_assessment_note" toName="chat" rows="10" maxSubmissions="1" showSubmitButton="false" />
</View>
</View>
<View className="htx-chat-sidepanel">
<View style="position:sticky;top:14px">
<View visibleWhen="region-selected" whenRole="user">
<Header value="Select errors:"/>
<Choices name="user_errors" toName="chat" choice="multiple">
<Choice value="Request Error" hint="Agent request is not correct or contains errors."/>
<Choice value="Other" hint="Other errors."/>
</Choices>
<Header value="Leave notes:"/>
<TextArea perRegion="true" name="user_errors_note" toName="chat" rows="10" />
</View>
<View visibleWhen="region-selected" whenRole="assistant">
<Header value="Select errors:"/>
<Choices name="llm_errors" toName="chat" choice="multiple">
<Choice value="Instruction Adherence" hint="The agent did not follow the instructions provided in the user prompt."/>
<Choice value="Format" hint="The message format is not correct or contains errors."/>
<Choice value="Hallucination" hint="The response contains information that is not supported by the provided context."/>
<Choice value="Bias" hint="The response contains bias or discrimination."/>
<Choice value="Toxicity" hint="The response contains toxic or offensive content."/>
<Choice value="PII" hint="The response contains Personally Identifiable Information (PII) or any other sensitive information."/>
<Choice value="Other" hint="Other errors."/>
</Choices>
<Header value="Leave notes:"/>
<TextArea perRegion="true" name="llm_errors_note" toName="chat" rows="10" />
</View>
<View visibleWhen="region-selected" whenRole="tool">
<Header value="Select errors:"/>
<Choices name="tool_errors" toName="chat" choice="multiple">
<Choice value="Tool Error" hint="Tool response is not correct or contains errors."/>
<Choice value="Other" hint="Other errors."/>
</Choices>
<Header value="Leave notes:"/>
<TextArea perRegion="true" name="tool_errors_note" toName="chat" rows="10" />
</View>
</View>
</View>
</View>
</View>"""
print("✓ Label configuration defined")✓ Label configuration defined
7. Push Tasks to Label Studio
Now we’ll create or update the Label Studio project and import all our traces. The import process:
- Check for existing project: If a project with the same name exists, we’ll use it
- Create project if needed: Set up a new project with our chat configuration
- Import tasks: Upload all traces with predictions as pre-annotations
- Generate labeling link: Provide direct access to the annotation interface
Understanding Label Studio Import
When we import tasks with predictions, Label Studio creates pre-annotations
that appear in the labeling interface. This is powerful because:
- Speeds up annotation: Annotators see the full conversation immediately
- Maintains context: All agent steps are visible and evaluable
- Enables comparison: Multiple annotators can independently assess the same trace
- Quality control: Supports consensus-based evaluation workflows
from label_studio_sdk.client import LabelStudio
# Initialize Label Studio client
ls = LabelStudio(
base_url=os.getenv("LABEL_STUDIO_URL"),
api_key=os.getenv("LABEL_STUDIO_API_KEY")
)
# Get or create project
project_name = os.getenv("LANGSMITH_PROJECT")
projects = list(ls.projects.list(title=project_name))
if len(projects) == 0:
print(f"Creating new project: {project_name}")
project_id = ls.projects.create(
title=project_name,
label_config=label_config
).id
else:
print(f"Using existing project: {project_name}")
project_id = projects[0].id
# Ensure project has correct label config
project = ls.projects.get(int(project_id))
if project.label_config.strip() == '<View></View>' or not project.label_config.strip():
print("Updating project with chat configuration...")
ls.projects.update(project_id, label_config=label_config)
# Import tasks
resp = ls.projects.import_tasks(project_id, request=tasks)
print(f"\n✓ Successfully imported {len(tasks)} tasks to Label Studio")
print(f'Go to: {os.getenv("LABEL_STUDIO_URL").rstrip("/")}/projects/{project_id}/data')
# Save tasks to file
with open('tasks.json', mode='w') as f:
json.dump(tasks, f, indent=2)Using existing project: pr-another-pamphlet-4
✓ Successfully imported 24 tasks to Label Studio
Go to: https://app.humansignal.com/projects/193998/data
8. Access the Labeling Interface
The Evaluation Workflow
Your traces are now ready for evaluation! The labeling interface provides:
For Each Message:
- Click any message to annotate errors specific to that step
- Select from predefined error categories (hallucination, format, bias, etc.)
- Add detailed notes explaining the issue
For Each Conversation:
- Overall assessment (Contains Errors / No Errors)
- General notes about the entire agent execution
Multi-User Collaboration:
- Multiple SMEs can annotate the same traces
- Compare annotations to measure inter-annotator agreement
- Use consensus to establish ground truth labels
Next Steps with Collected Data:
- Generate Reports: Analyze failure modes across all traces
- Design Prompts: Use annotated examples to improve agent instructions
- LLM-as-a-Judge: Create evaluation prompts based on SME feedback
- Quality Metrics: Track error rates over time as you iterate
- Dataset Creation: Build high-quality datasets for fine-tuning
# Generate the labeling URL
labeling_url = f"{os.getenv('LABEL_STUDIO_URL')}/projects/{project_id}/labeling"
print("\n" + "="*80)
print("🎉 SETUP COMPLETE!")
print("="*80)
print(f"\n📊 Project: {project_name}")
print(f"📝 Tasks imported: {resp.task_count}")
print(f"\n🔗 Start annotating:")
print(f" {labeling_url}")
print("\n💡 Share this link with your Subject Matter Experts to begin evaluation")
print("\n" + "="*80)================================================================================
🎉 SETUP COMPLETE!
================================================================================
📊 Project: pr-another-pamphlet-4
📝 Tasks imported: None
🔗 Start annotating:
https://app.humansignal.com/projects/193998/labeling
💡 Share this link with your Subject Matter Experts to begin evaluation
================================================================================
Summary
This tutorial demonstrated the complete workflow from agent execution to expert evaluation:
- ✓ Set up environment with LangSmith and Label Studio
- ✓ Ran a ReAct agent with Arxiv search capabilities
- ✓ Collected traces automatically via LangSmith
- ✓ Transformed traces into Label Studio’s annotation format
- ✓ Configured a specialized chat UI for failure mode analysis
- ✓ Imported tasks with pre-annotations
- ✓ Generated access link for SME annotation
Key Takeaway
While LangSmith excels at technical debugging during development, Label Studio provides the collaborative, expert-driven evaluation framework necessary for production AI systems. The combination creates a powerful workflow:
- Development: Engineers use LangSmith for debugging
- Evaluation: SMEs use Label Studio for quality assessment
- Iteration: Insights from both feed back into agent improvements
Happy evaluating! 🚀
References
- LangSmith
- Label Studio
- Evals FAQ
- Video tutorials about AI evals workflows: